# 前言
目标:将 HBase 的 fruit 表中的数据,通过 MR 筛选处理,导入到 HBase 中的 fruit2 表中
构建 Mapper 类,用于读取 fruit 表中的数据
package com.yaindream.mr2;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
/*** Created with IntelliJ IDEA.
* User: WangYu
* Date: 2020/6/15
* Time: 23:27
* Description:
*/
public class Fruit2Mapper extends TableMapper<ImmutableBytesWritable, Put> {
@Overrideprotected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
// 构建 put 对象Put put = new Put(key.get());
// 1. 获取数据for (Cell cell : value.rawCells()) {
// 2. 判断当前的 cell 是否为 “name” 列if ("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))) {
// 3. 给 put 对象赋值put.add(cell);
}}// 4. 写出context.write(key, put);
}}构建 Reducer 类,用于将处理过的数据写入到 fruit2 表中
package com.yaindream.mr2;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.NullWritable;
import java.io.IOException;
/*** Created with IntelliJ IDEA.
* User: WangYu
* Date: 2020/6/15
* Time: 23:27
* Description:
*/
public class Fruit2Reducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> {
@Overrideprotected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context) throws IOException, InterruptedException {
// 遍历写出for (Put value : values) {
context.write(NullWritable.get(), value);
}}}构建 Driver 类组装 Job
package com.yaindream.mr2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/*** Created with IntelliJ IDEA.
* User: WangYu
* Date: 2020/6/15
* Time: 23:27
* Description:
*/
public class Fruit2Driver implements Tool {
// 定义配置信息private Configuration configuration = null;
public int run(String[] args) throws Exception {
// 1. 获取 Job 对象Job job = Job.getInstance(configuration);
// 2. 设置主类路径job.setJarByClass(Fruit2Driver.class);
// 3. 设置 Mapper & 输出 KV 类型TableMapReduceUtil.initTableMapperJob(args[0],
new Scan(),
Fruit2Mapper.class,
ImmutableBytesWritable.class,
Put.class,
job);
// 4. 设置 Reducer & 输出的表TableMapReduceUtil.initTableReducerJob(args[1],
Fruit2Reducer.class,
job);
// 5. 提交任务boolean result = job.waitForCompletion(true);
return result ? 0 : 1;
}public void setConf(Configuration conf) {
configuration = conf;
}public Configuration getConf() {
return configuration;
}public static void main(String[] args) {
try {
Configuration configuration = new Configuration();
ToolRunner.run(configuration, new Fruit2Driver(), args);
} catch (Exception e) {
e.printStackTrace();
}}}将程序打包成 Jar 包并上传至集群。方法见 HBase-API 操作之与 MR 交互(二)
运行命令
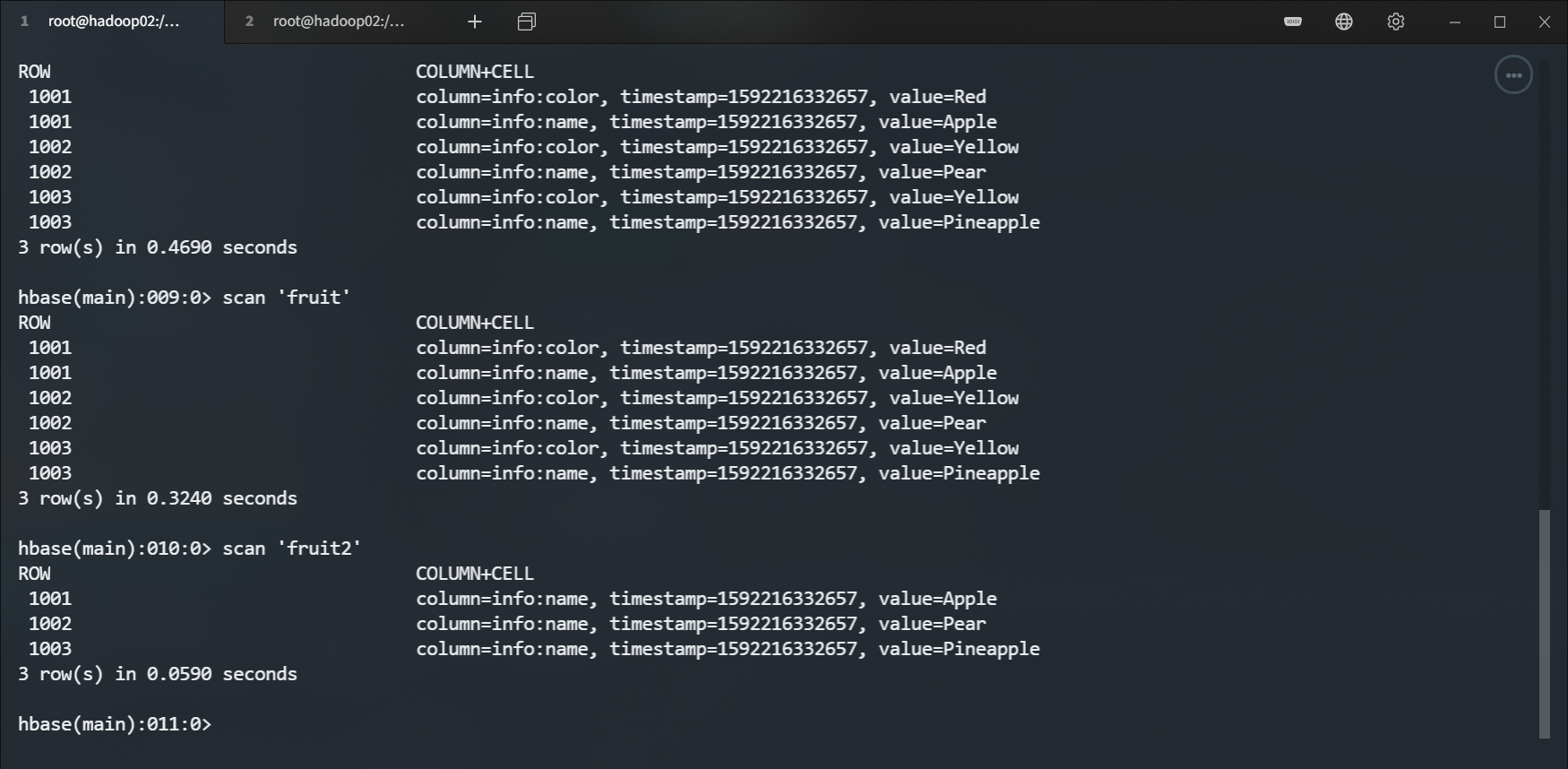
[root@hadoop02 hbase-1.3.1]# yarn jar hbase-demo-1.0-SNAPSHOT.jar com.yaindream.mr2.Fruit2Driver fruit fruit2运行结果
![]()
可以看到 name 列已经被我们筛选出来了