# 环境准备
目前能以学生优惠购买的云服务器有:
- 腾讯云一台
- 阿里云一台
- 华为云一台
- 百度云一台
学生身份能免费领取的云服务器有:
- 阿里云抗疫特惠云服务器一台
因为腾讯云和华为云的服务器有其他用途,所以剩余的三台用来实现 Hadoop 完全分布式运行模式,勉强够用。
云服务器环境如下:
- CentOS / 7.3 x86_64 (64bit)
- Java 1.8.0_144
- Hadoop 2.7.2
# 编写集群分发脚本
想要实现通过一个脚本将指定文件循环复制到所有节点的相同目录下。
在 /root 目录下创建 bin 目录,并在 bin 目录下创建文件 xsync
[root@hadoop02 bin]# mdkir bin
[root@hadoop02 bin]# cd bin/
[root@hadoop02 bin]# touch xsync
[root@hadoop02 bin]# vim xsync
在文件中编写如下代码
#!/bin/bash#1 获取输入参数个数,如果没有参数,直接退出pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi#2 获取文件名称p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称user=`whoami`
#5 循环for((host=3; host<5; host++)); do
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $user@hadoop0$host:$pdir
done注意:记得要把服务器地址和域名配置到 /etc/hosts 文件中
修改 xsync 具有执行权限
[root@hadoop02 bin]# chmod 755 xsync
调用脚本测试:将 /root/bin 目录复制到其他节点
[root@hadoop02 bin]# xsync /root/bin
# SSH 无密登录配置
无密登录原理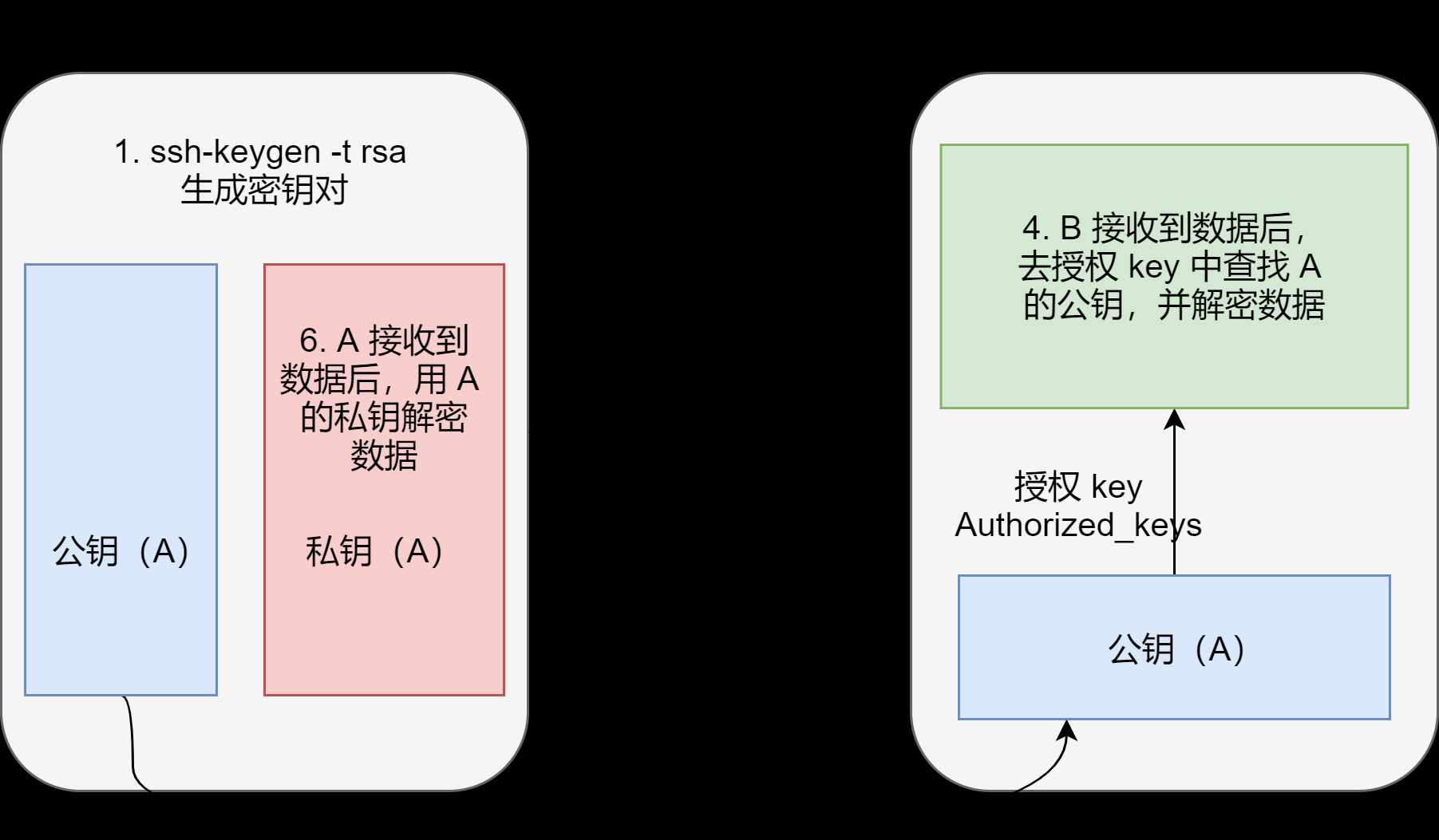
具体操作如下:
生成公钥和私钥
[root@hadoop02 .ssh]# ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件
id_rsa(私钥)、id_rsa.pub(公钥)将公钥拷贝到要免密登录的目标机器上
[root@hadoop02 .ssh]# ssh-copy-id hadoop02
[root@hadoop02 .ssh]# ssh-copy-id hadoop03
[root@hadoop02 .ssh]# ssh-copy-id hadoop04
测试一哈
[root@hadoop02 .ssh]# ssh hadoop03
无密登录的感觉是不是很爽哈哈。退出 ssh 用 exit 命令即可
注意了,还需要在 hadoop03 上采用 root 账号配置一下无密登录到 hadoop02、hadoop03、hadoop04 服务器上。为后面的集群群起做准备。
.ssh 文件夹下(~/.ssh)的文件功能解释
| 文件名 | 功能 |
|---|---|
| known_hosts | 记录 ssh 访问过计算机的公钥(public key) |
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过得无密登录服务器公钥 |
# 集群配置
# 集群规划部署
| hadoop02 | hadoop03 | hdoop04 | |
|---|---|---|---|
| HDFS | NameNode<br>DataNode | DataNode | SecondaryNameNode<br>DataNode |
| YARN | NodeManager | ResourceManager<br>NodeManager | NodeManager |
NameNode 和 SecondaryNameNode 的占用资源比较大,所以需要放在两台服务器上。ResourceManager 管理整个集群的资源,消耗资源也比较大,所以就需要放在第三台服务器上。
# 配置集群
# 核心配置文件
- 配置:
etc/hadoop/core-site.xml。在该文件中编写如下配置<!-- 指定 HDFS 中 NameNode 的地址 --><property><name>fs.defaultFS</name>
<value>hdfs://hadoop02:9000</value>
</property><!-- 指定 Hadoop 运行时产生文件的存储目录 --><property><name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
# HDFS 配置文件
- 配置:
etc/hadoop/hadoop-env.sh。修改 JAVA_HOME 路径export JAVA_HOME=/opt/module/jdk1.8.0_144
- 配置:
etc/hadoop/hdfs-site.xml。在该文件中编写如下配置<property><name>dfs.replication</name>
<value>3</value>
</property><!-- 指定 Hadoop 辅助名称节点主机配置 --><property><name>dfs.namenode.secondary.http-address</name>
<value>hadoop04:50090</value>
</property>
# YARN 配置文件
- 配置:
etc/hadoop/yarn-env.sh。配置 JAVA_HOME 路径export JAVA_HOME=/opt/module/jdk1.8.0_144
- 配置:
etc/hadoop/yarn-site.xml。在该文件中编写如下配置<!-- Reducer 获取数据的方式 --><property><name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property><!-- 指定 YARN 的 ResourceManager 的地址 --><property><name>yarn.resourcemanager.hostname</name>
<value>hadoop03</value>
</property>
# MapReduce 配置文件
- 配置:
etc/hadoop/mapred-env.sh。配置 JAVA_HOME 路径export JAVA_HOME=/opt/module/jdk1.8.0_144
- 配置:
etc/hadoop/mapred-site.xml。这个文件是对mapred-site.xml.template重命名得到的<!-- 指定 MR 运行在 YARN 上 --><property><name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
# 在集群上分发配置好的 Hadoop 配置文件
[root@hadoop02 hadoop-2.7.2]# xsync /opt/module/hadoop-2.7.2/etc/hadoop/ |
# 测试:集群单点启动
如果集群是第一次启动,需要格式化 NameNode
[root@hadoop02 hadoop-2.7.2]# hadoop namenode -format
注意:格式化之前需要关闭 NameNode 和 DataNode 等相关进程,然后删除 data 和 logs 文件夹。
在 hadoop02 上启动 NameNode
[root@hadoop02 hadoop-2.7.2]# hadoop-daemon.sh start namenode
在 hadoop02、hadoop03 以及 hadoop04 上分别启动 DataNode
[root@hadoop02 hadoop-2.7.2]# hadoop-daemon.sh start datanode
[root@hadoop03 hadoop-2.7.2]# hadoop-daemon.sh start datanode
[root@hadoop04 hadoop-2.7.2]# hadoop-daemon.sh start datanode
jps 命令查看都启动成功。测试没问题
# 踩坑!!!
我在 hadoop02 上启动 NameNode 没有启动成功,查看日志发现报错
java.net.BindException: Problem binding to [hadoop02:9000] java.net.BindException: Cannot assign requested address; For more details see: http://wiki.apache.org/hadoop/BindException | |
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) | |
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) | |
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) | |
at java.lang.reflect.Constructor.newInstance(Constructor.java:423) | |
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:792) | |
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:721) | |
at org.apache.hadoop.ipc.Server.bind(Server.java:425) | |
at org.apache.hadoop.ipc.Server$Listener.<init>(Server.java:574) | |
at org.apache.hadoop.ipc.Server.<init>(Server.java:2215) | |
at org.apache.hadoop.ipc.RPC$Server.<init>(RPC.java:938) | |
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server.<init>(ProtobufRpcEngine.java:534) | |
at org.apache.hadoop.ipc.ProtobufRpcEngine.getServer(ProtobufRpcEngine.java:509) | |
at org.apache.hadoop.ipc.RPC$Builder.build(RPC.java:783) | |
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.<init>(NameNodeRpcServer.java:344) | |
at org.apache.hadoop.hdfs.server.namenode.NameNode.createRpcServer(NameNode.java:673) | |
at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:646) | |
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:811) | |
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:795) | |
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1488) | |
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1554) | |
Caused by: java.net.BindException: Cannot assign requested address | |
at sun.nio.ch.Net.bind0(Native Method) | |
at sun.nio.ch.Net.bind(Net.java:433) | |
at sun.nio.ch.Net.bind(Net.java:425) | |
at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:223) | |
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74) | |
at org.apache.hadoop.ipc.Server.bind(Server.java:408) | |
... 13 more |
在网上找到了解决方案。这个问题的主要原因就是 Hadoop 是部署在云服务器 EC2 上的,在 EC2 上 ip 地址又分为 内网地址 和 外网地址 。问题就出在在 /ect/hosts 文件中。
在 /ect/hosts 设置 ip 与域名的匹配时要注意
- 在本机上的操作,都要设置成内网 ip 地址
- 其它机器上的操作,要设置成外网 ip 地址
所以具体配置如下:
| hadoop02 | hadoop03 | hdoop04 | |
|---|---|---|---|
| /etc/hosts | 内网 IP hadoop02<br> 外网 IP hadoop03<br > 外网 IP hadoop04 | 外网 IP hadoop02<br> 内网 IP hadoop03<br > 外网 IP hadoop04 | 外网 IP hadoop02<br> 外网 IP hadoop03<br > 内网 IP hadoop04 |
# 群起集群
# 配置 slaves
在 etc/hadoop/slaves 文件中配置如下内容。
hadoop02
hadoop03
hadoop04
注意:该文件中内容结尾不允许有空格,文件中不允许有空行。
# 同步所有节点
[root@hadoop02 hadoop-2.7.2]# xsync etc/hadoop/slaves |
# 启动集群
如果集群是第一次启动,需要格式化 NameNode(注意格式化之前,一定要先停止上次启动的所有 namenode 和 datanode 进程,然后再删除 data 和 logs 目录)
[root@hadoop02 hadoop-2.7.2]# bin/hdfs namenode -format
启动 HDFS
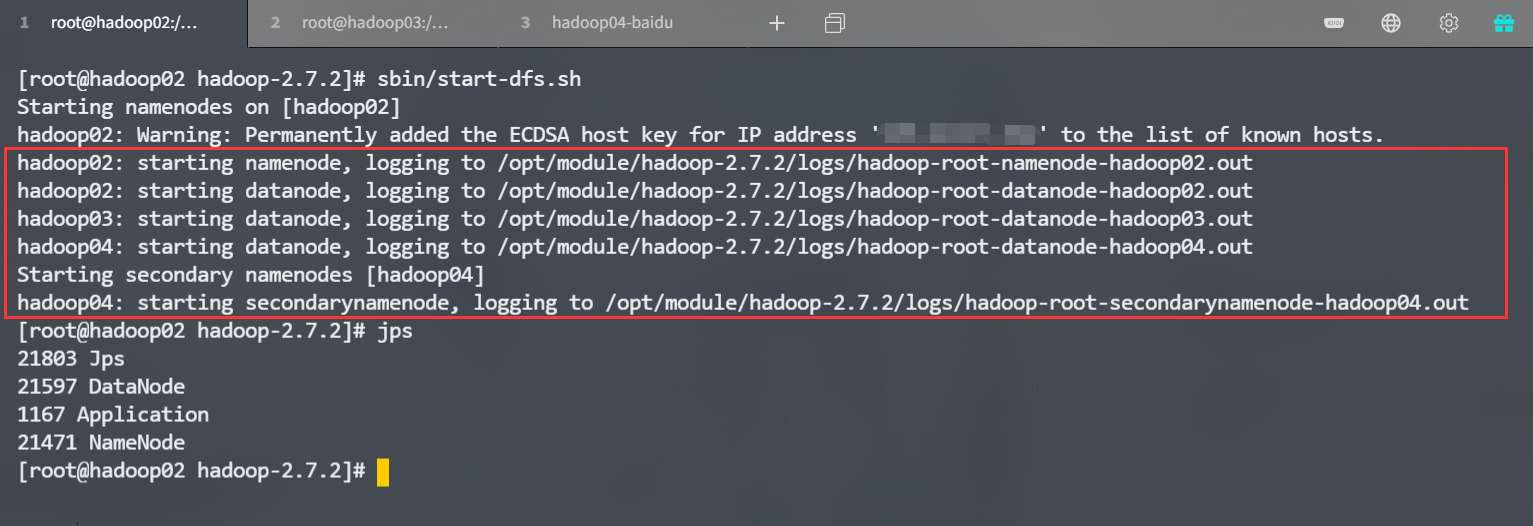
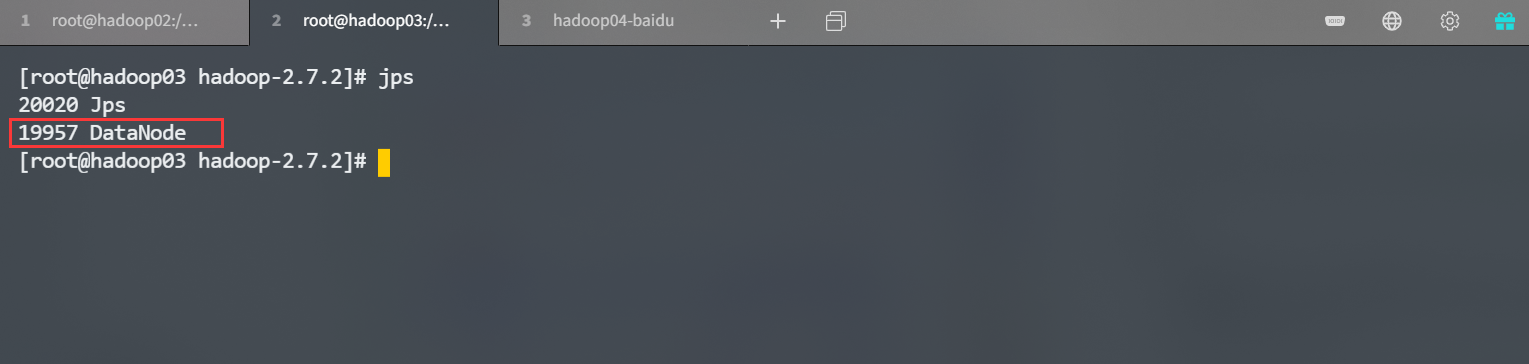
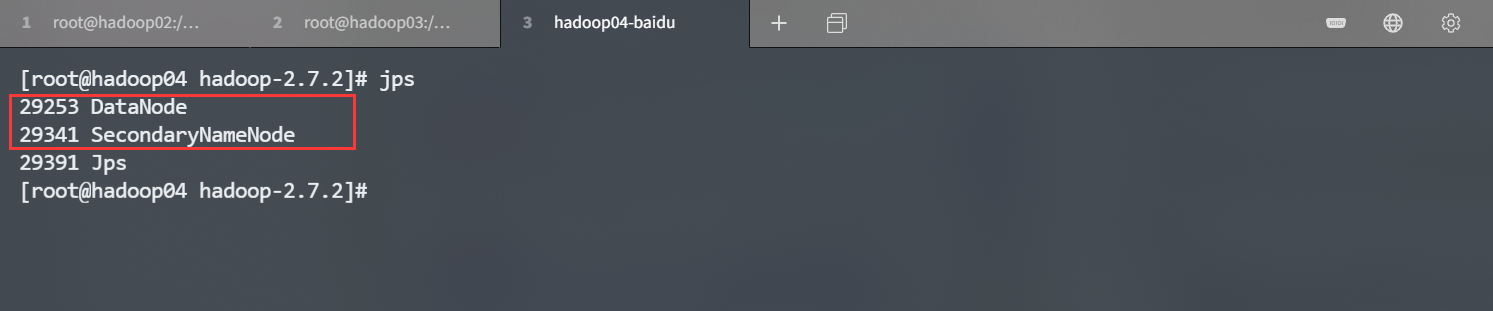
[root@hadoop02 hadoop-2.7.2]# sbin/start-dfs.sh
![]()
![]()
![]()
是不是和我们之前规划的部署是一模一样的,嘿嘿在 hadoop03 机器上启动 YARN。
# 注意一定要在 hadoop03 上启动[root@hadoop03 hadoop-2.7.2]# sbin/start-yarn.sh
注意,这里是在 hadoop03 机器上启动。因为如果 NameNode 和 ResourceManger 不是在同一台机器上,不能在 NameNode 上启动 YARN,应该在 ResouceManager 所在的机器上启动 YARN,所以需要在 hadoop03 上启动 YARN
在 Web 端查看 NameNode 和 SecondaryNameNode
http://hadoop02:50070/dfshealth.html#tab-overviewhttp://hadoop04:50090/status.html注意开放对应端口