# Spark 下载地址
- 官网地址 http://spark.apache.org/
- 文档查看地址 https://spark.apache.org/docs/2.1.1/
- 下载地址 https://spark.apache.org/downloads.html
我使用的 spark 版本是 2.1.1,如果想和我使用一样的版本,可以从这个百度云链接获取 https://pan.baidu.com/s/1ZDMKSeGofCfQZFo95DGvVw 提取码:bu90
# Spark 的重要角色
# Driver 驱动器
Spark 的驱动器是执行开发程序中的 main 方法的进程。它负责开发人员编写的用来创建 SparkContext、创建 RDD,以及进行 RDD 的转化操作和行动操作代码的执行。如果你是用 spark shell,那么当你启动 Spark shell 的时候,系统后台自启了一个 Spark 驱动器程序,就是在 Spark shell 中预加载的一个叫作 sc 的 SparkContext 对象。如果驱动器程序终止,那么 Spark 应用也就结束了。主要负责:
- 把用户程序转为作业(JOB)
- 跟踪 Executor 的运行情况
- 为执行器节点调度任务
- UI 展示应用运行状况
# Executor 执行器
Spark Executor 是一个工作进程,负责在 Spark 作业中运行任务,任务间相互独立。Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有 Executor 节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点上继续运行。主要负责:
- 负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程
- 通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在 Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算
# Local 模式
# 概述
Local 模式就是运行在一台计算机上的模式,通常就是用于在本机上练手和测试。它可以通过以下方式设置 Master。
- local:所有计算都运行在一个线程当中,没有任何并行计算,通常我们在本机执行一些测试代码,或者练手,就用这种模式
- loca [K]:指定使用几个线程来运行计算,比如 local [4] 就是运行 4 个 Worker 线程。通常我们的 Cpu 有几个 Core,就指定几个线程,最大化利用 Cpu 的计算能力
- local [*]:这种模式直接帮你按照 Cpu 最多 Cores 来设置线程数了。
# 安装使用
上传并解压 spark 安装包
[root@hadoop02 software]# tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module/
进入解压后的目录,直接运行官方求圆周率 PI 的案例
[root@hadoop02 spark-2.1.1-bin-hadoop2.7]# bin/spark-submit --class org.apache.spark.examples.SparkPi --executor-memory 1G --total-executor-cores 1 ./examples/jars/spark-examples_2.11-2.1.1.jar 100
基本语法:
bin/spark-submit \ --class <main-class> --master <master-url> \ --deploy-mode <deploy-mode> \ --conf <key>=<value> \ ... # other options <application-jar> \ [application-arguments]参数说明:
- --master:指定 Master 的地址,默认为 Local
- --class:应用的启动类(如 org.apache.spark.examples.SparkPi)
- --deploy-mode:是否发布你的驱动到 worker 节点 (cluster) 或者作为一个本地客户端 (client) (default: client)*
- --conf:任意的 Spark 配置属性, 格式 key=value. 如果值包含空格,可以加引号 "key=value"
- --executor-memory 1G:指定每个 executor 可用内存为 1G
- --total-executor-cores 1:指定每个 executor 使用的 cup 核数为 2 个
- application-jar:打包好的应用 jar,包含依赖。这个 URL 在集群中全局可见。比如 hdfs:// 共享存储系统, 如果是 file://path,那么所有的节点的 path 都包含同样的 jar
- application-arguments:传给 main () 方法的参数
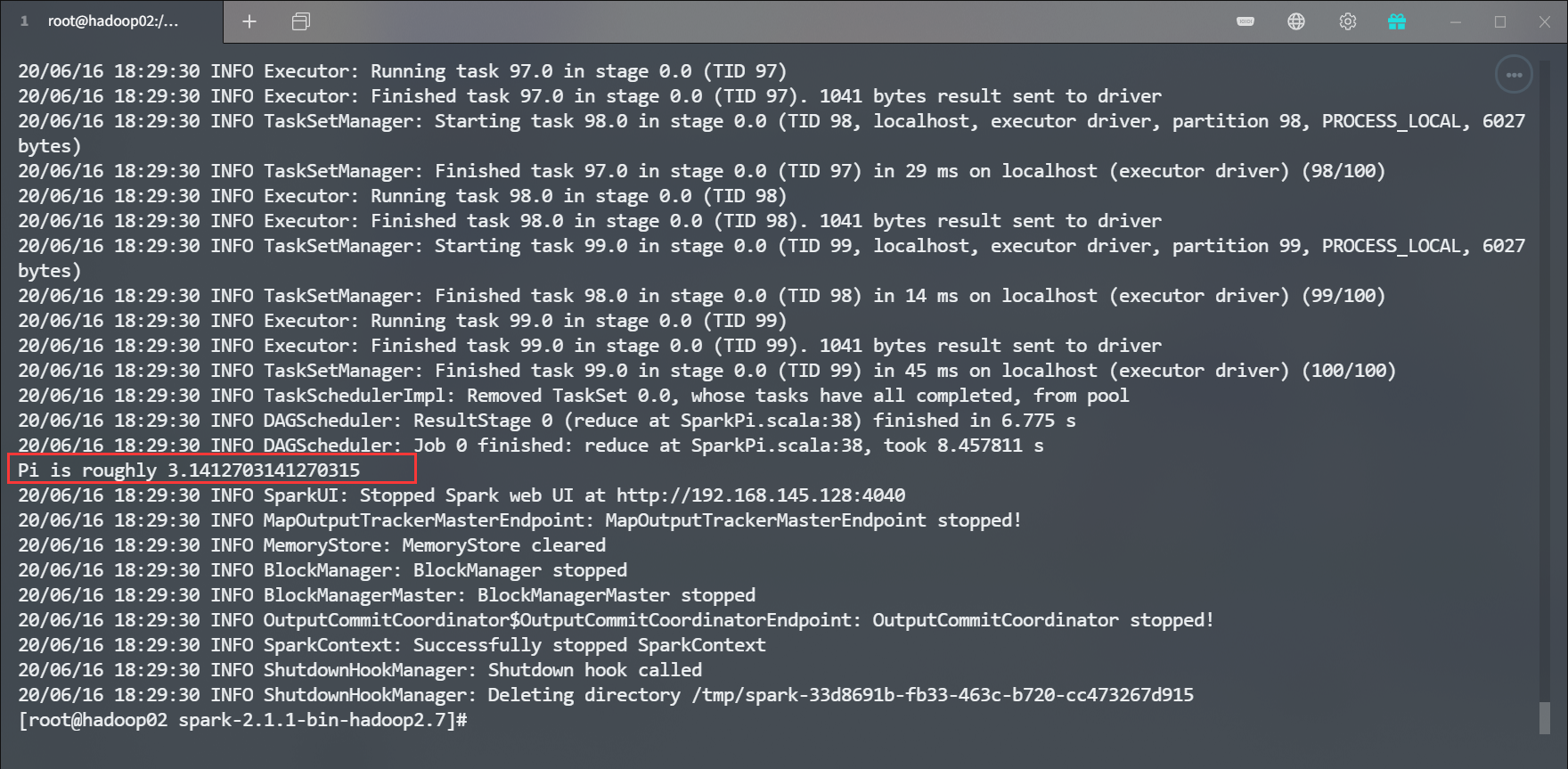
运行结果
![]()
该官方案例通过蒙特卡洛算法求解 PI
# spark shell 运行 WordCount 程序
准备文件
[root@hadoop02 spark-2.1.1-bin-hadoop2.7]# mkdir input
在 input 目录下创建两个文件 1.txt 和 2.txt,在文件中随意输入一些单词
hello world hello yain hello spark启动 spark shell
[root@hadoop02 spark-2.1.1-bin-hadoop2.7]# bin/spark-shell
![]()
可以登录
http://hadoop02:4040查看 web 界面运行 WordCount 程序
scala> sc.textFile("input").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).collect运行结果
res2: Array[(String, Int)] = Array((hello,3), (world,1), (spark,1), (yain,1))WordCount 程序分析
- textFile ("input"):读取本地文件 input 文件夹数据
- flatMap (_.split (" ")):压平操作,按照空格分割符将一行数据映射成一个个单词
- map ((_,1)):对每一个元素操作,将单词映射为元组
- reduceByKey(+):按照 key 将值进行聚合,相加
- collect:将数据收集到 Driver 端展示