参考资料:GAN.pdf
# 原理

# Q1. Where will D converge, given fixed G

# KL Divergence V.S. JS Divergence
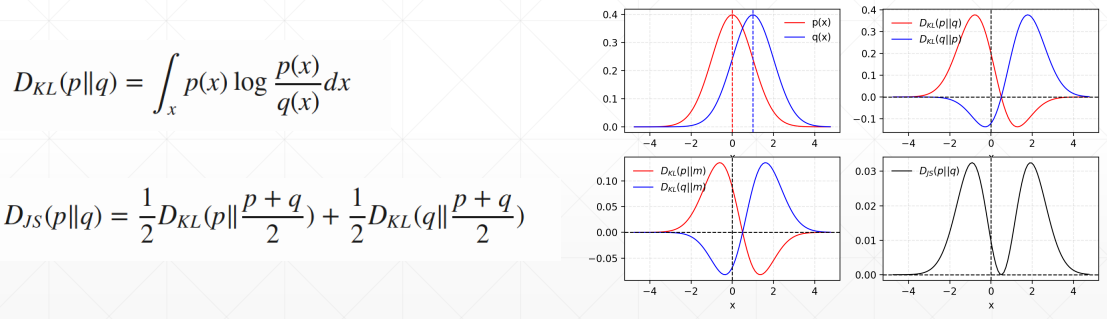
# Q2. Where will G converge, after optimal D

# GAN 会遇到的问题
训练不稳定,两个分布没有重叠的话,生成器就会长时间得不到更新
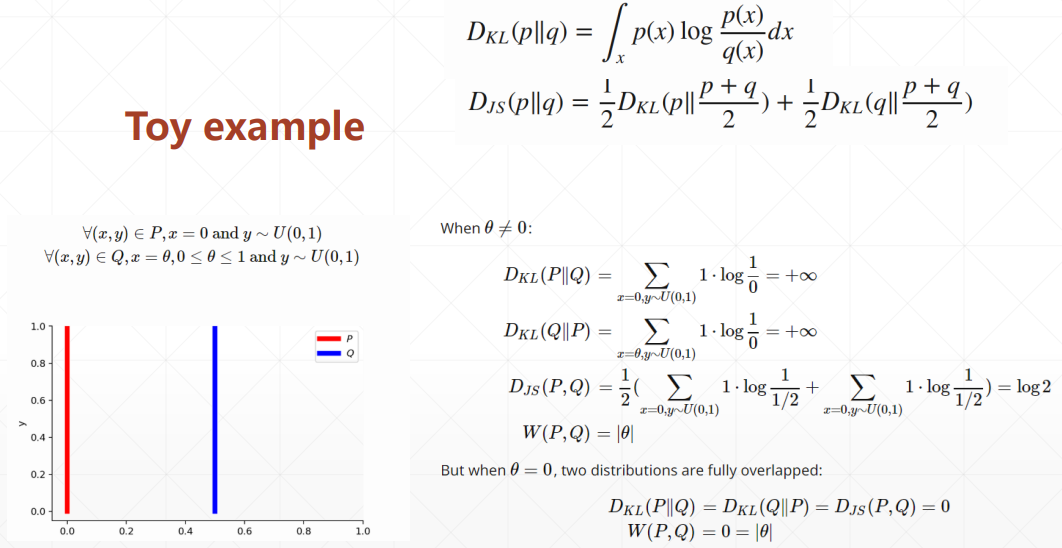
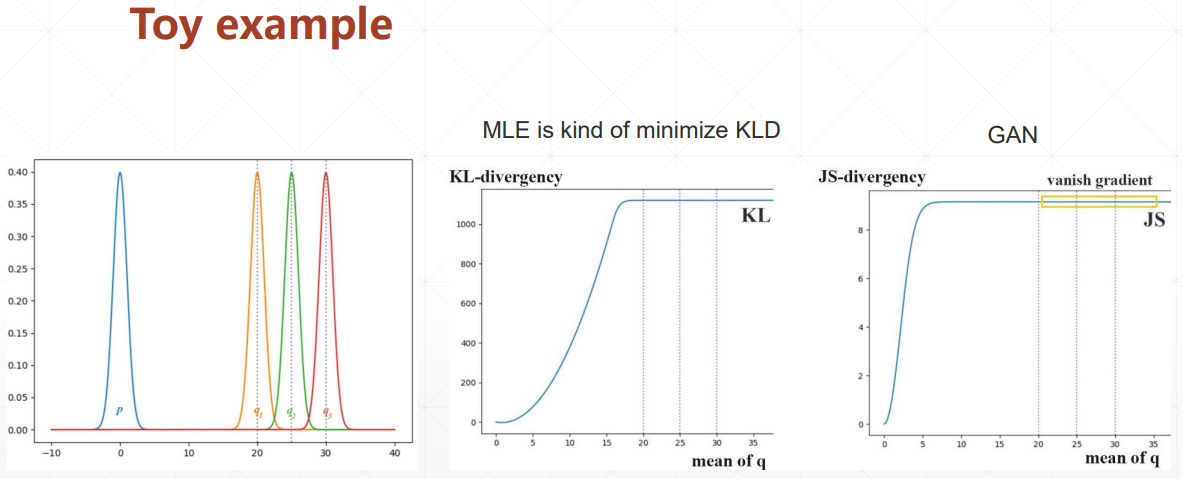
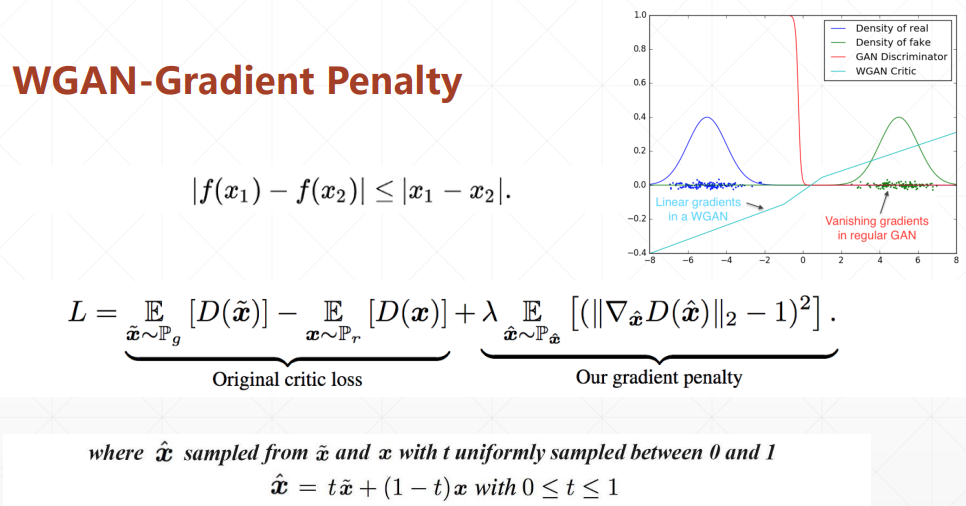
# WGAN
通过引入一个惩罚项缓解无法训练的问题
# 代码实战
# GAN
import torch | |
from torch import nn, optim, autograd | |
import numpy as np | |
import visdom | |
from torch.nn import functional as F | |
from matplotlib import pyplot as plt | |
import random | |
h_dim = 400 | |
batchsz = 512 | |
viz = visdom.Visdom() | |
class Generator(nn.Module): | |
def __init__(self): | |
super(Generator, self).__init__() | |
self.net = nn.Sequential( | |
nn.Linear(2, h_dim), | |
nn.ReLU(True), | |
nn.Linear(h_dim, h_dim), | |
nn.ReLU(True), | |
nn.Linear(h_dim, h_dim), | |
nn.ReLU(True), | |
nn.Linear(h_dim, 2), | |
) | |
def forward(self, z): | |
output = self.net(z) | |
return output | |
class Discriminator(nn.Module): | |
def __init__(self): | |
super(Discriminator, self).__init__() | |
self.net = nn.Sequential( | |
nn.Linear(2, h_dim), | |
nn.ReLU(True), | |
nn.Linear(h_dim, h_dim), | |
nn.ReLU(True), | |
nn.Linear(h_dim, h_dim), | |
nn.ReLU(True), | |
nn.Linear(h_dim, 1), | |
nn.Sigmoid() | |
) | |
def forward(self, x): | |
output = self.net(x) | |
return output.view(-1) | |
def data_generator(): | |
scale = 2. | |
centers = [ | |
(1, 0), | |
(-1, 0), | |
(0, 1), | |
(0, -1), | |
(1. / np.sqrt(2), 1. / np.sqrt(2)), | |
(1. / np.sqrt(2), -1. / np.sqrt(2)), | |
(-1. / np.sqrt(2), 1. / np.sqrt(2)), | |
(-1. / np.sqrt(2), -1. / np.sqrt(2)) | |
] | |
centers = [(scale * x, scale * y) for x, y in centers] | |
while True: | |
dataset = [] | |
for i in range(batchsz): | |
point = np.random.randn(2) * .02 | |
center = random.choice(centers) | |
point[0] += center[0] | |
point[1] += center[1] | |
dataset.append(point) | |
dataset = np.array(dataset, dtype='float32') | |
dataset /= 1.414 # stdev | |
yield dataset | |
# for i in range(100000//25): | |
# for x in range(-2, 3): | |
# for y in range(-2, 3): | |
# point = np.random.randn(2).astype(np.float32) * 0.05 | |
# point[0] += 2 * x | |
# point[1] += 2 * y | |
# dataset.append(point) | |
# | |
# dataset = np.array(dataset) | |
# print('dataset:', dataset.shape) | |
# viz.scatter(dataset, win='dataset', opts=dict(title='dataset', webgl=True)) | |
# | |
# while True: | |
# np.random.shuffle(dataset) | |
# | |
# for i in range(len(dataset)//batchsz): | |
# yield dataset[i*batchsz : (i+1)*batchsz] | |
def generate_image(D, G, xr, epoch): | |
""" | |
Generates and saves a plot of the true distribution, the generator, and the | |
critic. | |
""" | |
N_POINTS = 128 | |
RANGE = 3 | |
plt.clf() | |
points = np.zeros((N_POINTS, N_POINTS, 2), dtype='float32') | |
points[:, :, 0] = np.linspace(-RANGE, RANGE, N_POINTS)[:, None] | |
points[:, :, 1] = np.linspace(-RANGE, RANGE, N_POINTS)[None, :] | |
points = points.reshape((-1, 2)) | |
# (16384, 2) | |
# print('p:', points.shape) | |
# draw contour | |
with torch.no_grad(): | |
points = torch.Tensor(points).cuda() # [16384, 2] | |
disc_map = D(points).cpu().numpy() # [16384] | |
x = y = np.linspace(-RANGE, RANGE, N_POINTS) | |
cs = plt.contour(x, y, disc_map.reshape((len(x), len(y))).transpose()) | |
plt.clabel(cs, inline=1, fontsize=10) | |
# plt.colorbar() | |
# draw samples | |
with torch.no_grad(): | |
z = torch.randn(batchsz, 2).cuda() # [b, 2] | |
samples = G(z).cpu().numpy() # [b, 2] | |
plt.scatter(xr[:, 0], xr[:, 1], c='orange', marker='.') | |
plt.scatter(samples[:, 0], samples[:, 1], c='green', marker='+') | |
viz.matplot(plt, win='contour', opts=dict(title='p(x):%d'%epoch)) | |
def weights_init(m): | |
if isinstance(m, nn.Linear): | |
# m.weight.data.normal_(0.0, 0.02) | |
nn.init.kaiming_normal_(m.weight) | |
m.bias.data.fill_(0) | |
def gradient_penalty(D, xr, xf): | |
""" | |
:param D: | |
:param xr: | |
:param xf: | |
:return: | |
""" | |
LAMBDA = 0.3 | |
# only constrait for Discriminator | |
xf = xf.detach() | |
xr = xr.detach() | |
# [b, 1] => [b, 2] | |
alpha = torch.rand(batchsz, 1).cuda() | |
alpha = alpha.expand_as(xr) | |
interpolates = alpha * xr + ((1 - alpha) * xf) | |
interpolates.requires_grad_() | |
disc_interpolates = D(interpolates) | |
gradients = autograd.grad(outputs=disc_interpolates, inputs=interpolates, | |
grad_outputs=torch.ones_like(disc_interpolates), | |
create_graph=True, retain_graph=True, only_inputs=True)[0] | |
gp = ((gradients.norm(2, dim=1) - 1) ** 2).mean() * LAMBDA | |
return gp | |
def main(): | |
torch.manual_seed(23) | |
np.random.seed(23) | |
G = Generator().cuda() | |
D = Discriminator().cuda() | |
G.apply(weights_init) | |
D.apply(weights_init) | |
optim_G = optim.Adam(G.parameters(), lr=1e-3, betas=(0.5, 0.9)) | |
optim_D = optim.Adam(D.parameters(), lr=1e-3, betas=(0.5, 0.9)) | |
data_iter = data_generator() | |
print('batch:', next(data_iter).shape) | |
viz.line([[0,0]], [0], win='loss', opts=dict(title='loss', | |
legend=['D', 'G'])) | |
for epoch in range(50000): | |
# 1. train discriminator for k steps | |
for _ in range(5): | |
x = next(data_iter) | |
xr = torch.from_numpy(x).cuda() | |
# [b] | |
predr = (D(xr)) | |
# max log(lossr) | |
lossr = - (predr.mean()) | |
# [b, 2] | |
z = torch.randn(batchsz, 2).cuda() | |
# stop gradient on G | |
# [b, 2] | |
xf = G(z).detach() | |
# [b] | |
predf = (D(xf)) | |
# min predf | |
lossf = (predf.mean()) | |
# gradient penalty | |
gp = gradient_penalty(D, xr, xf) | |
loss_D = lossr + lossf + gp | |
optim_D.zero_grad() | |
loss_D.backward() | |
# for p in D.parameters(): | |
# print(p.grad.norm()) | |
optim_D.step() | |
# 2. train Generator | |
z = torch.randn(batchsz, 2).cuda() | |
xf = G(z) | |
predf = (D(xf)) | |
# max predf | |
loss_G = - (predf.mean()) | |
optim_G.zero_grad() | |
loss_G.backward() | |
optim_G.step() | |
if epoch % 100 == 0: | |
viz.line([[loss_D.item(), loss_G.item()]], [epoch], win='loss', update='append') | |
generate_image(D, G, xr, epoch) | |
print(loss_D.item(), loss_G.item()) | |
if __name__ == '__main__': | |
main() |
# WGAN
import torch | |
from torch import nn, optim, autograd | |
import numpy as np | |
import visdom | |
from torch.nn import functional as F | |
from matplotlib import pyplot as plt | |
import random | |
h_dim = 400 | |
batchsz = 512 | |
viz = visdom.Visdom() | |
class Generator(nn.Module): | |
def __init__(self): | |
super(Generator, self).__init__() | |
self.net = nn.Sequential( | |
nn.Linear(2, h_dim), | |
nn.ReLU(True), | |
nn.Linear(h_dim, h_dim), | |
nn.ReLU(True), | |
nn.Linear(h_dim, h_dim), | |
nn.ReLU(True), | |
nn.Linear(h_dim, 2), | |
) | |
def forward(self, z): | |
output = self.net(z) | |
return output | |
class Discriminator(nn.Module): | |
def __init__(self): | |
super(Discriminator, self).__init__() | |
self.net = nn.Sequential( | |
nn.Linear(2, h_dim), | |
nn.ReLU(True), | |
nn.Linear(h_dim, h_dim), | |
nn.ReLU(True), | |
nn.Linear(h_dim, h_dim), | |
nn.ReLU(True), | |
nn.Linear(h_dim, 1), | |
nn.Sigmoid() | |
) | |
def forward(self, x): | |
output = self.net(x) | |
return output.view(-1) | |
def data_generator(): | |
scale = 2. | |
centers = [ | |
(1, 0), | |
(-1, 0), | |
(0, 1), | |
(0, -1), | |
(1. / np.sqrt(2), 1. / np.sqrt(2)), | |
(1. / np.sqrt(2), -1. / np.sqrt(2)), | |
(-1. / np.sqrt(2), 1. / np.sqrt(2)), | |
(-1. / np.sqrt(2), -1. / np.sqrt(2)) | |
] | |
centers = [(scale * x, scale * y) for x, y in centers] | |
while True: | |
dataset = [] | |
for i in range(batchsz): | |
point = np.random.randn(2) * .02 | |
center = random.choice(centers) | |
point[0] += center[0] | |
point[1] += center[1] | |
dataset.append(point) | |
dataset = np.array(dataset, dtype='float32') | |
dataset /= 1.414 # stdev | |
yield dataset | |
# for i in range(100000//25): | |
# for x in range(-2, 3): | |
# for y in range(-2, 3): | |
# point = np.random.randn(2).astype(np.float32) * 0.05 | |
# point[0] += 2 * x | |
# point[1] += 2 * y | |
# dataset.append(point) | |
# | |
# dataset = np.array(dataset) | |
# print('dataset:', dataset.shape) | |
# viz.scatter(dataset, win='dataset', opts=dict(title='dataset', webgl=True)) | |
# | |
# while True: | |
# np.random.shuffle(dataset) | |
# | |
# for i in range(len(dataset)//batchsz): | |
# yield dataset[i*batchsz : (i+1)*batchsz] | |
def generate_image(D, G, xr, epoch): | |
""" | |
Generates and saves a plot of the true distribution, the generator, and the | |
critic. | |
""" | |
N_POINTS = 128 | |
RANGE = 3 | |
plt.clf() | |
points = np.zeros((N_POINTS, N_POINTS, 2), dtype='float32') | |
points[:, :, 0] = np.linspace(-RANGE, RANGE, N_POINTS)[:, None] | |
points[:, :, 1] = np.linspace(-RANGE, RANGE, N_POINTS)[None, :] | |
points = points.reshape((-1, 2)) | |
# (16384, 2) | |
# print('p:', points.shape) | |
# draw contour | |
with torch.no_grad(): | |
points = torch.Tensor(points).cuda() # [16384, 2] | |
disc_map = D(points).cpu().numpy() # [16384] | |
x = y = np.linspace(-RANGE, RANGE, N_POINTS) | |
cs = plt.contour(x, y, disc_map.reshape((len(x), len(y))).transpose()) | |
plt.clabel(cs, inline=1, fontsize=10) | |
# plt.colorbar() | |
# draw samples | |
with torch.no_grad(): | |
z = torch.randn(batchsz, 2).cuda() # [b, 2] | |
samples = G(z).cpu().numpy() # [b, 2] | |
plt.scatter(xr[:, 0], xr[:, 1], c='orange', marker='.') | |
plt.scatter(samples[:, 0], samples[:, 1], c='green', marker='+') | |
viz.matplot(plt, win='contour', opts=dict(title='p(x):%d'%epoch)) | |
def weights_init(m): | |
if isinstance(m, nn.Linear): | |
# m.weight.data.normal_(0.0, 0.02) | |
nn.init.kaiming_normal_(m.weight) | |
m.bias.data.fill_(0) | |
def gradient_penalty(D, xr, xf): | |
""" | |
:param D: | |
:param xr: | |
:param xf: | |
:return: | |
""" | |
LAMBDA = 0.3 | |
# only constrait for Discriminator | |
xf = xf.detach() | |
xr = xr.detach() | |
# [b, 1] => [b, 2] | |
alpha = torch.rand(batchsz, 1).cuda() | |
alpha = alpha.expand_as(xr) | |
interpolates = alpha * xr + ((1 - alpha) * xf) | |
interpolates.requires_grad_() | |
disc_interpolates = D(interpolates) | |
gradients = autograd.grad(outputs=disc_interpolates, inputs=interpolates, | |
grad_outputs=torch.ones_like(disc_interpolates), | |
create_graph=True, retain_graph=True, only_inputs=True)[0] | |
gp = ((gradients.norm(2, dim=1) - 1) ** 2).mean() * LAMBDA | |
return gp | |
def main(): | |
torch.manual_seed(23) | |
np.random.seed(23) | |
G = Generator().cuda() | |
D = Discriminator().cuda() | |
G.apply(weights_init) | |
D.apply(weights_init) | |
optim_G = optim.Adam(G.parameters(), lr=1e-3, betas=(0.5, 0.9)) | |
optim_D = optim.Adam(D.parameters(), lr=1e-3, betas=(0.5, 0.9)) | |
data_iter = data_generator() | |
print('batch:', next(data_iter).shape) | |
viz.line([[0,0]], [0], win='loss', opts=dict(title='loss', | |
legend=['D', 'G'])) | |
for epoch in range(50000): | |
# 1. train discriminator for k steps | |
for _ in range(5): | |
x = next(data_iter) | |
xr = torch.from_numpy(x).cuda() | |
# [b] | |
predr = (D(xr)) | |
# max log(lossr) | |
lossr = - (predr.mean()) | |
# [b, 2] | |
z = torch.randn(batchsz, 2).cuda() | |
# stop gradient on G | |
# [b, 2] | |
xf = G(z).detach() | |
# [b] | |
predf = (D(xf)) | |
# min predf | |
lossf = (predf.mean()) | |
# gradient penalty | |
gp = gradient_penalty(D, xr, xf) | |
loss_D = lossr + lossf + gp | |
optim_D.zero_grad() | |
loss_D.backward() | |
# for p in D.parameters(): | |
# print(p.grad.norm()) | |
optim_D.step() | |
# 2. train Generator | |
z = torch.randn(batchsz, 2).cuda() | |
xf = G(z) | |
predf = (D(xf)) | |
# max predf | |
loss_G = - (predf.mean()) | |
optim_G.zero_grad() | |
loss_G.backward() | |
optim_G.step() | |
if epoch % 100 == 0: | |
viz.line([[loss_D.item(), loss_G.item()]], [epoch], win='loss', update='append') | |
generate_image(D, G, xr, epoch) | |
print(loss_D.item(), loss_G.item()) | |
if __name__ == '__main__': | |
main() |