# 注意以下几点
- 创建自己的类 MyDataset,继承自 torch.utils.data.Dataset,以便可以读取我们自己的数据集
- 在 Resnet50 的基础上,更改最后一层全连接层,添加 RelU 激活函数,Dropout,输出纬度更改为 [batchsz, 3],并将 dim=1 进行 Softmax 操作。
- 如果使用 GPU 设备,注意 model, loss_func, 和数据都要转移到 GPU 上,可以使用 cuda () 函数或 to (device)。
- pytorch 的 dropout 的参数和 tf 的参数刚好相反
- 使用如下方式保存和加载模型:
# save | |
torch.save({ | |
'epoch': epoch, | |
'model_state_dict': model.state_dict(), | |
'optimizer_state_dict': optimizer.state_dict(), | |
'loss': loss, | |
... | |
}, PATH) | |
# load | |
model = TheModelClass(*args, **kwargs) | |
optimizer = TheOptimizerClass(*args, **kwargs) | |
checkpoint = torch.load(PATH) | |
model.load_state_dict(checkpoint['model_state_dict']) | |
optimizer.load_state_dict(checkpoint['optimizer_state_dict']) | |
epoch = checkpoint['epoch'] | |
loss = checkpoint['loss'] | |
model.eval() | |
# - or - | |
model.train() |
# 代码
import torch | |
from torch.utils.data import DataLoader | |
from torchvision import datasets | |
from torchvision import transforms | |
from torch import nn, optim | |
import torchvision.models as models | |
from matplotlib import pyplot as plt | |
import numpy as np | |
import mydataset | |
import myutils | |
import time | |
def read_data(batchsz=32): | |
# 加载训练数据 | |
train_data = mydataset.MyDataset('./data/train.txt', transform=transforms.Compose([ | |
# 数据增强:随机水平翻转 | |
transforms.RandomHorizontalFlip(), | |
# 数据增强:随机垂直翻转 | |
transforms.RandomVerticalFlip(), | |
# 转换成张量 | |
transforms.ToTensor(), | |
# 数据增强,像素归一化,均值 / 方差 | |
transforms.Normalize([0.485, 0.456, 0.406], | |
[0.229, 0.224, 0.225]) | |
])) | |
train_loader = DataLoader(train_data, batch_size=batchsz, shuffle=True) | |
# 加载测试数据 | |
test_data = mydataset.MyDataset('./data/test.txt', transform=transforms.Compose([ | |
# 数据增强:随机水平翻转 | |
transforms.RandomHorizontalFlip(), | |
# 数据增强:随机垂直翻转 | |
transforms.RandomVerticalFlip(), | |
# 转换成张量 | |
transforms.ToTensor(), | |
# 数据增强,像素归一化,均值 / 方差 | |
transforms.Normalize([0.485, 0.456, 0.406], | |
[0.229, 0.224, 0.225]) | |
])) | |
test_loader = DataLoader(test_data, batch_size=batchsz, shuffle=True) | |
x, label = iter(train_loader).next() | |
print('x:', x.shape, 'label:', label.shape) | |
print("数据加载完毕...") | |
return train_data, train_loader, test_data, test_loader | |
def load_model(model_path): | |
# 初始化模型 | |
model = models.resnet50() | |
# 更改最后一层全连接层 | |
# 首先获取输入参数 | |
fc_inputs = model.fc.in_features | |
# 添加全连接层,RelU 激活函数,Dropout | |
model.fc = nn.Sequential( | |
nn.Linear(fc_inputs, 256), | |
nn.ReLU(), | |
nn.BatchNorm1d(256), | |
# 注意 pytorch 的 dropout 的参数和 tf 的参数刚好相反 | |
nn.Dropout(0.3), | |
nn.Linear(256, 3), | |
nn.Softmax(1) | |
) | |
# 开启 GPU 加速 | |
device = torch.device('cuda') | |
model.to(device) | |
# 定义优化器 | |
optimizer = optim.Adam(model.parameters(), lr=1e-3) | |
epoch = 0 | |
record = [] | |
best_epoch = 0 | |
best_mae = 100.0 | |
# 预训练模型存在 | |
if myutils.fileExists(model_path): | |
# 加载预训练模型参数 | |
checkpoint = torch.load(model_path) | |
model.load_state_dict(checkpoint['model_state_dict']) | |
optimizer.load_state_dict(checkpoint['optimizer_state_dict']) | |
epoch = checkpoint['epoch'] | |
record = checkpoint['record'] | |
best_epoch = checkpoint['best_epoch'] | |
best_mae = checkpoint['best_mae'] | |
model.to(device) | |
# 定义损失函数 | |
loss_func = nn.MSELoss().to(device) | |
return model, optimizer, loss_func, record, { | |
'device': device, | |
'epoch': epoch, | |
'best_epoch': best_epoch, | |
'best_mae': best_mae, | |
} | |
# 参数分别是 模型 优化器 损失函数 CPU/GPU 设备 记录员 最好的 mae 最好的 mae 对应的 epoch batchsize 迭代次数 预训练模型的迭代次数 | |
def train_and_valid(model, optimizer, loss_func, device, record=[], best_mae=100, best_epoch=0, batchsz=32, epochs=10, old_epoch=0): | |
# 加载数据 | |
train_data, train_loader, test_data, test_loader = read_data(batchsz=batchsz) | |
# 记录训练结果 | |
record = record | |
# 记录最好的 epoch 和 mae | |
best_mae = best_mae | |
best_epoch = best_epoch | |
# 开始迭代 | |
for epoch in range(epochs): | |
epoch_start = time.time() | |
train_loss = 0.0 | |
train_mae = 0.0 | |
test_loss = 0.0 | |
test_mae = 0.0 | |
# 切换为训练模式 | |
model.train() | |
for batchidx, (x, label) in enumerate(train_loader): | |
# 获取 batch 数据 | |
x, label = x.to(device), label.to(device) | |
# 送入模型得到结果 [batch, 3] | |
logits = model(x) | |
# 计算 loss | |
loss = loss_func(logits, label) | |
# 反向传播标准三步,梯度清零,计算梯度,更新权值参数 | |
optimizer.zero_grad() | |
loss.backward() | |
optimizer.step() | |
# 累加 loss | |
train_loss += loss.item() * x.size(0) | |
# 累加 mae | |
train_mae += (logits - label).abs().sum().item() | |
# 进度条更新进度 | |
myutils.progressBar(batchsz * (batchidx + 1), len(train_data)) | |
# 切换成验证模式 | |
model.eval() | |
with torch.no_grad(): | |
# test | |
total_error = 0 | |
total_num = 0 | |
for batchidx, (x, label) in enumerate(test_loader): | |
# 获取 batch 数据 | |
x, label = x.to(device), label.to(device) | |
# 送入模型得到结果 [batch, 3] | |
logits = model(x) | |
# 计算 loss | |
loss = loss_func(logits, label) | |
# 累加 loss | |
test_loss += loss.item() * x.size(0) | |
# 累加 mae | |
test_mae += (logits - label).abs().sum().item() | |
# 进度条更新进度 | |
myutils.progressBar(batchsz * (batchidx + 1), len(test_data)) | |
# 计算平均值 | |
avg_train_loss = train_loss / len(train_data) | |
avg_train_mae = train_mae / len(train_data) | |
avg_test_loss = test_loss / len(test_data) | |
avg_test_mae = test_mae / len(test_data) | |
# 记录 | |
record.append([avg_train_loss, avg_test_loss, avg_train_mae, avg_test_mae]) | |
# 记录最好的 epoch 和 mae | |
if avg_test_mae < best_mae : | |
best_mae = avg_test_mae | |
best_epoch = old_epoch + epoch + 1 | |
epoch_end = time.time() | |
# 打印本轮训练结果 | |
print("Epoch: {:03d}/{:03d} Time: {:.4f}s ============> train_loss: {:.4f} train_mae: {:.4f} / val_loss: {:.4f} val_mae {:.4f}".format( | |
old_epoch + epoch + 1, old_epoch + epochs, epoch_end - epoch_start, avg_train_loss, avg_train_mae, avg_test_loss, avg_test_mae)) | |
# 打印最好的 mae 和 epoch | |
print("Best MAE for validation : {:.4f} at epoch {:03d}".format(best_mae, best_epoch)) | |
return model, optimizer, record, best_epoch, best_mae | |
if __name__ == '__main__': | |
epochs = 5 | |
batchsz = 32 | |
model_path = 'models/model_06071135_5.pth' | |
# 加载模型 | |
model, optimizer, loss_func, record, model_dict = load_model(model_path) | |
print(model_dict) | |
# 开始训练 | |
trained_model, optimizer, record, best_epoch, best_mae = train_and_valid( | |
model = model, | |
optimizer = optimizer, | |
loss_func = loss_func, | |
record = record, | |
device = model_dict['device'], | |
best_mae = model_dict['best_mae'], | |
best_epoch = model_dict['best_epoch'], | |
old_epoch = model_dict['epoch'], | |
batchsz = batchsz, | |
epochs = epochs | |
) | |
model_save_path = 'models/model_{}_{}.pth'.format(myutils.getTime(), model_dict['epoch']+epochs) | |
# 保存模型参数,优化器的参数也要保存哦,还有一些其他的超参数 | |
torch.save({ | |
'epoch': model_dict['epoch']+epochs, | |
'model_state_dict': trained_model.state_dict(), | |
'optimizer_state_dict': optimizer.state_dict(), | |
'record': record, | |
'best_epoch': best_epoch, | |
'best_mae': best_mae | |
}, model_save_path) | |
# 绘制折线图 | |
myutils.show_loss_and_mae(record) |
# 初步训练结果
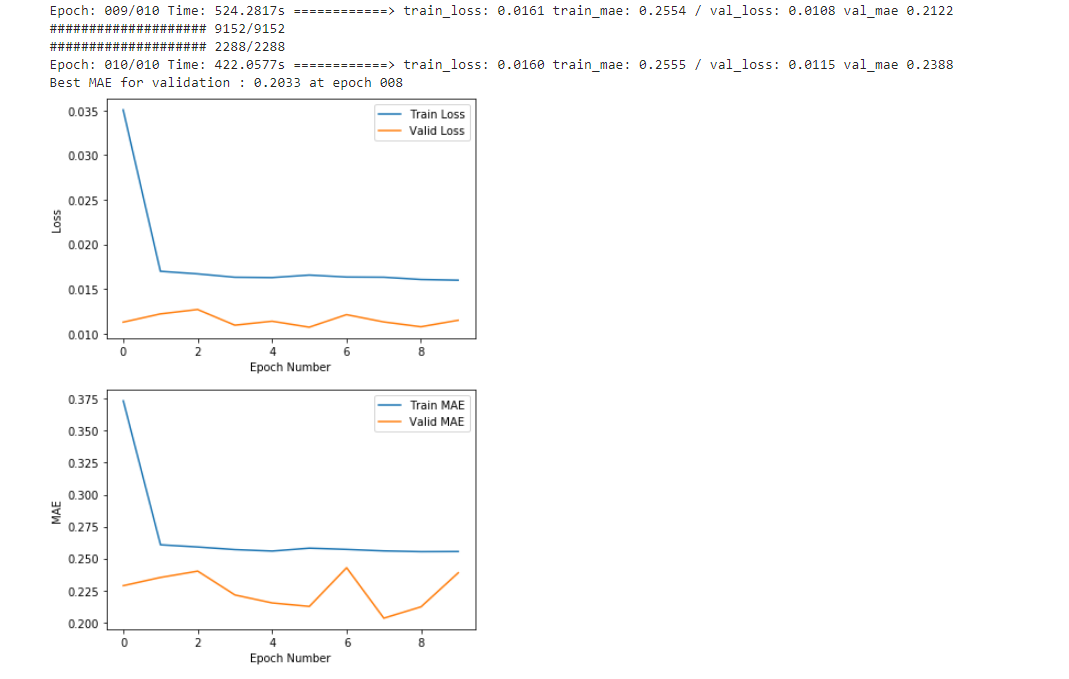
效果并不是让人特别满意,后面再继续优化吧